Category training
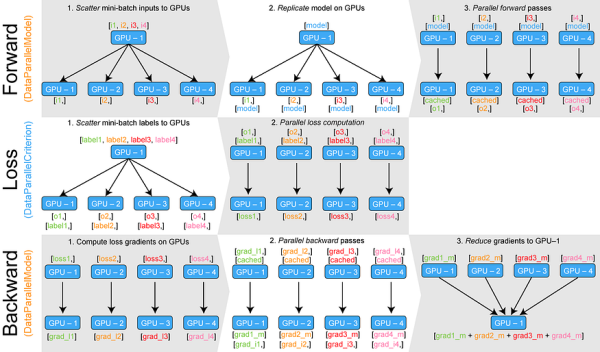
Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups… Source: Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups | by Thomas Wolf | HuggingFace | Medium Read… Continue Reading →
Tutorial – train your own llama.cpp mini-ggml-model from scratch! by u/Evening_Ad6637 in LocalLLaMA Here I show how to train with llama.cpp your mini ggml model from scratch! these are currently very small models (20 mb when quantized) and I think… Continue Reading →