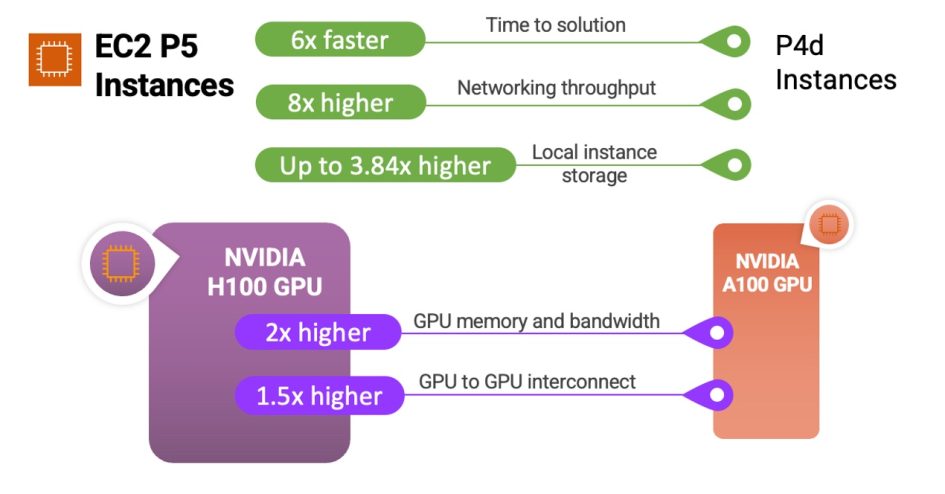
In March 2023, AWS and NVIDIA announced a multipart collaboration focused on building the most scalable, on-demand artificial intelligence (AI) infrastructure optimized for training increasingly complex large language models (LLMs) and developing generative AI applications.
We preannounced Amazon Elastic Compute Cloud (Amazon EC2) P5 instances powered by NVIDIA H100 Tensor Core GPUs and AWS’s latest networking and scalability that will deliver up to 20 exaflops of compute performance for building and training the largest machine learning (ML) models. This announcement is the product of more than a decade of collaboration between AWS and NVIDIA, delivering the visual computing, AI, and high performance computing (HPC) clusters across the Cluster GPU (cg1) instances (2010), G2 (2013), P2 (2016), P3 (2017), G3 (2017), P3dn (2018), G4 (2019), P4 (2020), G5 (2021), and P4de instances (2022).
Most notably, ML model sizes are now reaching trillions of parameters. But this complexity has increased customers’ time